


A zebra is not a horse painted with stripes
What Chomsky didn't grasp about ChatGPT and its workings. The main reason we are unable to understand LLMs is the confusion between statistics and patterns. Part One.


1. The right and the wrong
One year after Chomsky’s New York Times op-ed on ChatGPT, written with I. Roberts and J. Watumull1, it’s time to look at what he got right, but mostly what he got wrong. This is not polemic in intent; it is a good opportunity to touch on several persistent errors we can still find in many recent texts about Artificial Intelligence (AI).
There is an old Romanian anecdote about a farmer who, for the first time in his life, saw a camel in a circus. He shouted: "That thing does not exist!" Faced with something entirely new, our minds can only create analogies to grasp the elusive reality. This need is so strong that when we encounter something radically new and different, we tend to reject it, ignore it, or force it into an existing concept. Something similar has happened when some of our greatest minds have been confronted with the uncanny ability of ChatGPT to answer any question. Chomsky knows better than our Romanian farmer. A year ago, when he first saw a camel, he wrote something we can sum up like this: “This is just a horse because it’s got four legs and carries things for us! It is indeed a lumbering horse that has never known green grass, but if you look at its basic form and function, it’s a horse!”
One point he made in the op-ed was that AGI is not even close. He was right about that: All the ensuing drama about the AGI threat was a tempest in a teapot. If anything, only the idea of regulation moved on. The problem is in us, not the machines: we don’t regulate the guns that are going to shoot us by themselves; we regulate the people who have access to the guns and who might shoot us for no good reason.
It is also plainly clear that Chomsky was right to say that LLMs are not even the least intelligent. However, his argument does not show what an LLM truly is (he gets it wrong), instead, that is not what many people claim it to be: some sort of intelligence. This negative definition approach fails to point out that any LLM is a model to store knowledge in a new format and not an intelligence you can ask about causal explanations of things. We stored knowledge before in books, libraries and databases, and nobody thought to argue that books or databases aren’t intelligent because they can’t offer explanations by themselves. Something similar happens with Google. Even if we ask things and use question marks, the results of the search are not answers to our question, but a list best fitting the words in the search. By arguing that stored knowledge is not intelligent, Chomsky proves at best that knowledge is not understanding, something trivial.
At the core of many consistent misunderstandings is the fact that the name “ChatGPT” designates at the same time the LLM developed by OpenAI and the entire group of distinct functions needed to make the LLM usable: the interface (API), post-processing and fine-tuning algorithms design to frame the prompt, together with the LLM itself. The following diagram, showing how an LLM is accessed during training and while we use it, may be helpful in understanding that, in proper terms, what we call a Large Language Model is an entity becoming entirely “frozen” once training ends:
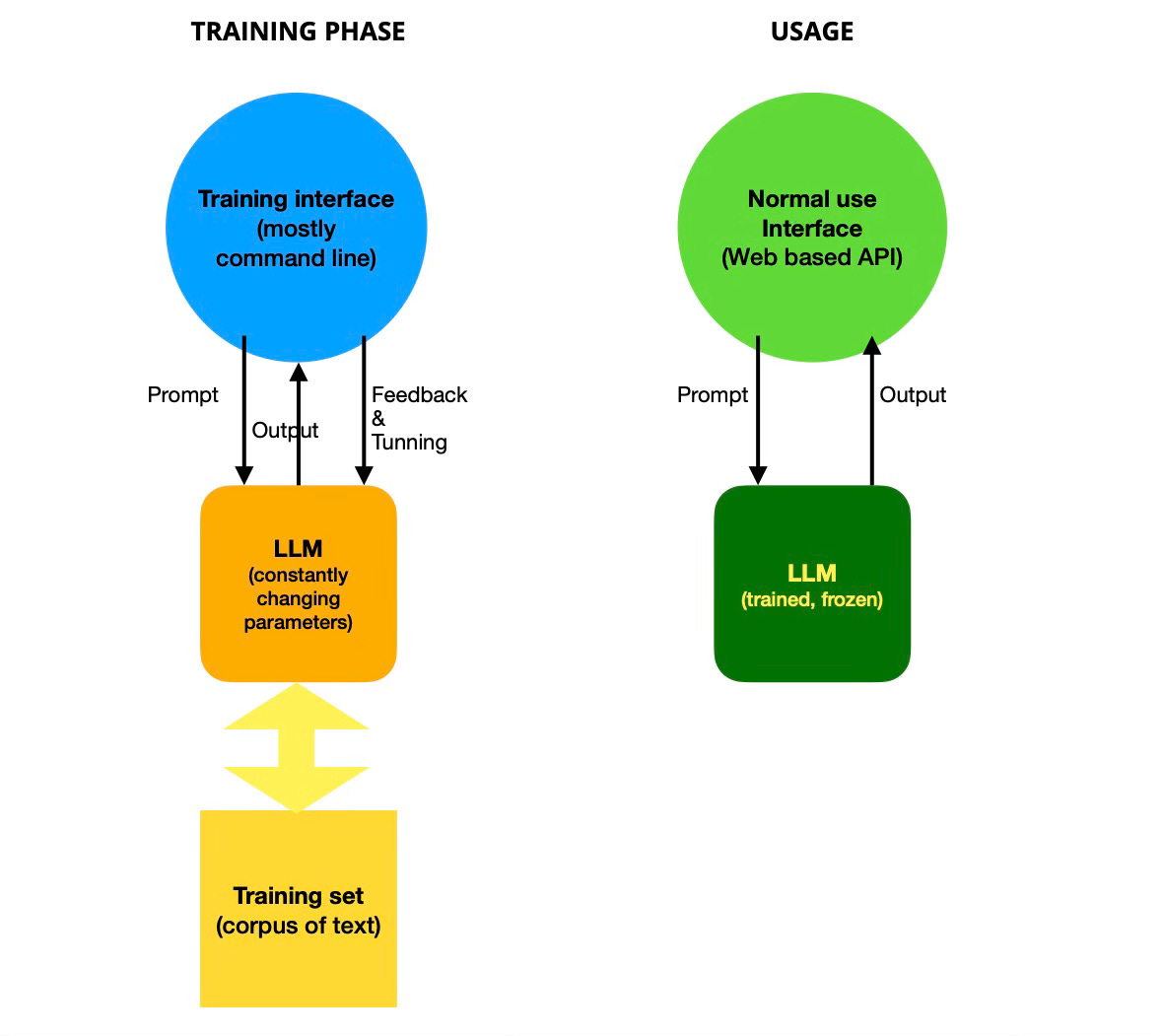
Now back to Chomsky’s argument: His approach relies heavily on comparisons to the human mind, overlooking a crucial fact: Language Models (LLMs) like the one at the core of ChatGPT are unprecedented entities, distinct from anything encountered before. While many perceive the browser window and algorithms taking in our prompts and generating “answers” as the LLM itself, that is merely the interface - the underlying mechanisms facilitating interactions with the true core, the Language Model. The Language Model in itself, developed during training, acts as an inert repository of knowledge distilled from vast textual data. However, akin to a dormant database or a library awaiting queries, it remains inactive without an interface to access and decode its stored information. Thus, dismissing the intelligence of the interface is also a trivial argument.
In reality, the true wonder, the language model itself, is invisible; as invisible as are Google page rank databases — where the real Google genius lies2 — to our browsers; most people are unaware of their existence. It is telling that the application named ChatGPT we all access over the web uses a small amount of energy - the interface does not need a lot of computing power as its operations are relatively simple - while training the model can consume inordinate amounts of energy.
The process of training is more like forging a very tough metal into a powerful sword: all the energy goes into manufacturing, and once ready, there is comparatively little effort to use the sword. And the real question to ask is not if the tool we call LLM is intelligent because it is obvious it is not. The one-million-dollar question is: what is this tool and why it works so well?
But instead of answering this, Chomsky’s objective seems to be to prove that LLMs are not intelligent because they are something that they are not. In his words:
The human mind is not, like ChatGPT and its ilk, a lumbering statistical pattern-matching engine gorging itself on hundreds of terabytes of data and extrapolating the most likely conversational answer to a scientific question.
A Large Language Model is not a statistical engine. Even the word “statistical” is a misnomer in this context3. If we choose to stay within the realm of zoological metaphors of cognition, we can say that the reason people still think it is “statistical” even today, has something to do with the idea that a zebra is just a horse painted with stripes: Our use of analogy or inference has become unconscious, and from a technique of understanding has become knowledge itself. We take the tool for the truth, and a zebra turns from something “unknown, like a striped horse”, into a literally striped horse.4 This is a pervasive problem in many recent writings on AI and deserves to be detailed. So in the following, we’ll explain what an LLM seems to be5, and not what it is not.
For that, we need firstly to explain why pattern recognition is not probabilities or statistics, but a very efficient way to react to a changing environment for all living creatures. We’ll then show that the core method on which every modern LLM is built, “word embedding”, has profound similarities to a technique discovered by Carl Gustav Jung at the beginning of the 20th century, the “free words association” method. The fundamental nature of an LLM is its associative word patterns structure, improved to a point of complexity completely opaque to us, but still associative in essence. The human mind shares with an LLM some sort of associative description of reality, and this is the reason an LLM looks like ‘it knows’ things: it associates words similarly to how objects of reality (or imagination) are associated in human descriptions of reality, or, in what we generally call “knowledge”.
2. We Keep Getting Statistics and Probability Wrong
“Statistics” refers to a set of mathematical techniques to analyze a distribution of measured parameters in a massive set. It solves the need to work with huge data sets (populations) without describing their points individually, replacing them instead with collective parameters. When we say that “25% of the population is over the age of 65”, we are using statistics. It is also statistics (of a molecular kind) when we say “The temperature in this room is 21 degrees C or the standard deviation of temperature in this room is 2”. So, statistics is mostly reducing large data sets to some simple collective variables.
The term “probability” refers to the result of a repeated measurement in a controlled environment. Flipping a coin, drawing a card, or measuring the position of an electron on a screen are all measurements. (we call these measurements “events” in probability theory)
Probability is indeed related to certain more likely patterns that a system can follow under certain conditions, leading to more likely outcomes, i.e., measurement results; for example, throwing a slightly asymmetric coin will display a different pattern of results than a symmetric one. But patterns are not statistical, what defines them is not their repeated occurrence in some measurement, but their structure. (more about this later on)
Chomsky’s description of how an LLM works is:
...they take huge amounts of data, search for patterns in it and become increasingly proficient at generating statistically probable outputs
Firstly, even if it may sound right, “statistically probable” makes sense only in one situation: if the LLM uses statistical parameters to describe every word and its relationship with the entire text and then calculates probabilities for each word when generating text. True, its model is numerical, only that not any numerical model is statistical. It would be statistics if, for example, the word “grammar” is described as “next to the word ’of’ ” an average of 2 times per 1000 occurrences, with certain standard deviations and other statistical data increasing the relevance of the description. From this, the algorithm can conclude that the probability of the word “of” to follow next to “grammar” is 2/1000. Huge tables describing these probabilities for each word in relation to every other word will be needed. The machine will then pick the word with the highest probability of occurrence in the training set. We’ll see later on in this text that such a model is possible but extremely costly and slow, generating poor results when constructing long phrases. The statistical model was used in one form or another by the first chatbots, but this is not how an LLM works.
Something is “statistical” in nature if using some sort of collective parameters to describe a vast set. And we call “probabilistic” some sort of individual prediction regarding a member of a set. If anything, ChatGPT may be some sort of “probabilistic machine” rather than a statistical one. But even this analogy loses something essential about the true nature of LLMs.
3. Pattern recognition is not about probabilities.
The real reason LLMs have scared the crap out of so many smart people is that no one really understands how they work, or more precisely, what the reason for their uncanny output realism is.
AI has excelled in complex tasks long before LLMs emerged. Take autonomous driving: it’s remarkable how computers adapt to never-before-seen situations on busy streets. Instead of exhaustive calculations, they rely on pattern recognition, much like our brains do. The crux of this achievement lies in a simple yet powerful concept shared by our brains and AI systems: rather than meticulously analyzing every detail and solving complex equations, we rely on pattern recognition. This approach, unlike deterministic methods, allows for quick adaptation to complex and changing environments without the burden of computational complexity. By leveraging an extensive library of patterns and their associated outcomes, AI systems can swiftly respond to specific situations by instantly matching patterns and executing complex reactions (patterns in themselves), bypassing the need for cumbersome calculations. This is what a tiger does (we chose to stay with the zoological metaphors) when it hunts, not solving equations about its optimal trajectory6.
When maneuvering into a tight parking spot, our brains rely on patterns acquired in training and during everyday use of the car, rather than statistical analysis. Relying solely on statistics to park a car would involve tedious calculations based on various measurements like space and timing and tons of data stored from all previous parking experiences. This method would likely result in prolonged maneuvering and potential damage to the vehicle, as no two spaces are the same.
Many individuals conflate “probabilities” and “patterns” due to their association with recurring events, but their fundamental descriptions of such events differ significantly. A pattern delineates the structure of an event itself, independent of time, and serves to distinguish one event type, including multiple events, from another. In contrast, probabilities quantify the repeated occurrence of the same individual event over time. While the occurrence of a pattern can be analyzed statically to derive probabilities, this approach is not employed in AI systems. Probabilities are mostly inconsequential for technologies like Tesla’s autopilot; what truly matters is identifying the appropriate pattern and determining a corresponding course of action. Similar to how a tiger hunts, constantly aligning patterns in reality with patterns of its body movements, the significance of a pattern in Tesla’s autopilot isn’t dictated only by how frequently it appeared during training, but rather by its potential risk for accidents. The weight of a pattern is not determined by statistics; instead, it is evaluated based on its safety implications.
The autopilot AI’s performance in real life is directly related to its ability to react to exceptional events, many with no statistical history. This is also what makes a good driver, incidentally. It should be clear that statistic analysis does not play a crucial role in “pattern-recognition-based” machines.
In a general sense, patterns are complex sequences of events (or collections of instances of events) that are similar in some abstract, sometimes hidden way. Their nature is somewhat topological, rather than geometric or arithmetic7. They tell us nothing about the probability of any event involving a certain pattern, but rather about the tendency of objects or events in experience to appear together. We can have “patterns of behavior” for an individual, but it’s absurd to predict the probability of an individual doing any particular thing based on those patterns8 Probabilities are useful when working with big populations and data sets, and not with individual cases.9 Patterns, on the contrary, work really well on isolated cases, but they tell us nothing about probabilities.10 So that an LLM is not even a “probabilistic” machine” but rather a “pattern discerning machine”.
It is worth noting that there is another word that is very often misused when people describe how LLMs work: "prediction". For example, ChatGPT's own description of what a "forward pass" is says
Pass each batch of input sequences through the model to compute predictions for the next token or sequence of tokens.
But this is no prediction, it’s just an actual output the trainer (or the machine by itself) then compares to some actual expected output. Think about basic training of an AI to recognise people gender in photos. You input into the machine learning program a photo and the system responds with “male” or “female”11. It is clear to us the machine’s answer is no prediction in any way. But when you train a LLM, instead of having two answers to choose from, the machine has an enormous range of possibilities to pick the next word in a phrase its constructing as answer to a prompt. Instead of you giving feedback, the machine employs specific methods to compare its answer against actual phrases in the training corpus, and rate it & change some internal parameters accordingly. The machine is learning by itself. Then, once trained, it looks for words matching the specific patterns of the words in front of it (prompt & other generated words), and picks them in a way certain computed parameters are minimised. Even if to us it can look like “it predicts the next word” it’s simply “picking a word best matching a pattern”. “Prediction” has no place in this because there is no computed probability at any time. It may look as a harmless issue but this perpetuates the fundamental misunderstanding of LLMs as “statistic” or “probabilistic” machines, ultimately preventing us to see them for what they are.
4. Patterns in language models
Before moving on, we need to have at least a broad understanding of how an LLM works first. There are two theoretical breakthroughs at the heart of modern LLMs:
the concept of word embedding
the concept of “transformers
Transformers are quite recent and may be the main reason for ChatGPT’s12 breakthrough more than a year ago. Without going into details, it’s a set of algorithms and techniques implementing a “self-attention mechanism”, joined in what we call “a model architecture”, to keep the output in the context of the prompt, avoiding the problem that plagued early LLMs: loss of coherence.
But the key lies in “word embedding”, which is an algorithm (or more precisely, a set of algorithms) that measures some abstract “distances”13 between words in a body of text (called a “training set”, TS). In simple terms, the words “simple” and “terms” tend to be next to each other more often than “simple” and “horse” in a large text. But it gets much more complicated and simple at the same time.
It’s complicated because this distance is not one-dimensional, like the actual distance between words in a text, as in the “simple”/“terms” example above, but rather a distance in a virtual space with thousands of dimensions. Its expression is often a measurement of the angle between the vectors of two words, each vector being a huge matrix, with thousands of rows and columns. This ultimately encodes how a word relates to any other in many different ways (like position patterns in sentences, or even across the entire training text of billions of pages). The data is so complex and overwhelming that we can’t make sense of it by looking at the numbers, they’re just huge matrices (or even tensors) filled with values. Countless calculations including gradients in this thousand-fold space and something we call “loss function” are performed. How this mashup of numbers gives relevant answers to our questions, and how it “knows” things, seems beyond comprehension.
It’s also simple because this “distance” that an LLM uses to look for patterns in a text has been known conceptually since 1921. We fail to see the forest because of the trees. As far as I know, no one has yet realized that word embedding is essentially a complex mathematical model for what we have been calling "free word association" for the last century. But it is applied to an existing corpus of text, rather than to spontaneous human responses to single-word prompts.
5. Knowledge as Patterns of Word Associations
Following CG Jung’s first article on the subject in 192114, the technique became an important tool in the diagnosis of psychological “complexes” and later, in the last decades of the century, in semantic research aimed at understanding how meaning arises in language. I have not researched this in-depth, but I believe that the theory of “word embedding” is directly related to this type of semantic research.
The field is fascinating in itself, but far from our specific interest here. In a nutshell, there are average times that any subject takes to respond to a prompt (such as saying “mouse” after the doctor says “cat”), and this time increases dramatically when the prompt is related to a problem the subject is having (such as a long pause after the researcher says “father”). This has proven a valuable and efficient tool in countless clinical cases since Jung discovered it.
But almost no one has asked why it works. Why do we expect people to respond quickly to prompted words, where these words are coming from and, more importantly, why do these words make sense most of the time?
Recent research15 points to the answer: the way we associate words is at the core of our description of reality. For example, we can get from the above-cited study the probability for a particular word to appear after a given prompt. We can think of the inverse of these probabilities as “distances”: the greater the probability, the “closer” the words are. These “distances” correspond to actual distances among real objects in the real world, or to how they relate to each other.
For example, almost no one said “glass” after the prompt “beer” because we do not usually drink beer out of glasses. The closest words were “wine”, “drunk”, “party” and “can”. All describe probable realities around the real beer (the research was done on students, in case you wonder about what kind of reality it describes).
At the same time, the probability that “dinner” would elicit a response of “lunch” was 10%, while the reverse was 27%. This is normal once you realize that dinner follows lunch, and this is simply a “time direction” of the sequence of events in reality. In this example, we begin to see that not only “distance” is encoded in these probabilities, but also natural temporal order.
But this kind of research is a very crude way to build word association models, and is challenging to improve on: You have to ask millions of people billions of prompts, and then mash all that data into some kind of probability database to get a more relevant model of word association as a description of reality. (This may be what Chomsky had in mind when claiming an LLM is a “statistic machine”)
However, once you realize that you don’t have to do that because you already have a huge corpus of text all over the Internet, where words are already in precise positions in billions of sentences coming out of people’s heads, you’re all set for the eventual discovery of the Large Language Model. All you need is to jump from probabilities to patterns and turn some AI software (which by definition has been specialized in pattern recognition for decades) into some sort of “word distribution pattern” recognition machine; this is the crucial step, moving from statistic analysis (free word association experiments) to pattern recognition (a LLM of a large corpus of text).
Since we started with the observation that word association in people’s minds encodes some representation of actual reality16, it dawns on you that knowledge is to be found in the way words are associated in our texts more than in the words themselves. It would be shown in the second part of this article that the knowledge lies not even in the words that make up the sentence, but in the associated words triggered in our minds when we read the sentence, words that are never written and spoken.
For now, let’s summarize that knowledge resides in the way we associate words with each other, in the patterns they associate with in our written texts, and not in the rules we use to form sentences or in the words themselves. There is another simple proof of this: the “me Tarzan, you Jane” level of language used by a tourist with rudimentary knowledge of a foreign language. While open to many possible interpretations, even phrases like “me sleep bed money” make some sense. This is possible largely because the way these words are associated resembles patterns of how we associate the corresponding objects and actions in reality. We can see here an important feature of all patterns: because they are topological rather than arithmetic in nature, they are recognizable even after dramatic “bending” and stretching, as in “me sleep bed money”. This is precisely why a Tesla can react correctly to an entirely new situation, or why we can read a text with many vowels missing: meaning lies not in the details.17
In sum, statistics are not probabilities, and probabilities are not patterns. But there is more: knowledge, memory, and meaning are all “features” of the patterns of word association in our minds or texts. A LLM is, in fact, a word association pattern machine, capable of turning vast amounts of text into a mathematical model describing all the possible patterns of association in the texts. This is the profound reason why LLM can produce real knowledge and look intelligent, even when it isn’t. A language model is an entirely new “state of aggregation” of knowledge, not a database of probabilities, as Chomsky believes. Nor is it a mysterious conscience emerging from the machine, as too many of those writing on the subject claim. This is what the next essay will try to explain in more detail.
6. To follow in Part Two, “What an LLM teaches us about the human mind”
It is also for part two of this essay to prove Chomsky wrong in one of the most fundamental claims in his op-ed from a year ago, when he said the operating system of our brain is grammar. In his words:
For instance, a young child acquiring a language is developing — unconsciously, automatically and speedily from minuscule data — a grammar, a stupendously sophisticated system of logical principles and parameters. This grammar can be understood as an expression of the innate, genetically installed “operating system” that endows humans with the capacity to generate complex sentences and long trains of thought. When linguists seek to develop a theory for why a given language works as it does (“Why are these — but not those — sentences considered grammatical?”), they are building consciously and laboriously an explicit version of the grammar that the child builds instinctively and with minimal exposure to information. The child’s operating system is completely different from that of a machine learning program.”
We’ll show that if there is something like an operating system for our brain, it is associative in essence and has little to do with logic and hard rules. This is precisely the reason a child's brain is so adept at absorbing knowledge and learning a language. Logic is a byproduct of this system and not its infrastructure and takes years of intense training to develop abstract thinking, something a 5-year-old does not need to naturally learn a second language in a couple of months. The whole idea of a child developing “a grammar, a stupendously sophisticated system of logical principles and parameters” is similar to the idea that when riding a bike, the said child makes complex and fast calculations to determine its optimum position in order not to fall. It’s patterns, not logic.
Even though the article was co-authored, since the title attributes it to Chomsky, I will continue to use the singular and refer to him only as the author.
To somebody coming straight from the beginning of the century, Google search performance today will be nothing short of miraculous. We fail to realize this because the progress was incremental, and we know a lot about its reasons, but it’s not difficult to see why somebody unaccustomed to its inner workings may argue that the Google search engine is intelligent.
In all honesty, at the time Chomsky wrote his op-ed, I believed the same. But contradicting Chomsky is by far more interesting than proving myself wrong. However, one should be warned that the idea is still pervasive in many technical texts about LLMs. ChatGPT owns explanations refer to it: “Overall, the vector representations of words in a word embedding model are learned from the distributional properties of the training data, and they reflect the statistical patterns of word co-occurrences within that data.”
It’s only the absurdity these unconscious analogies can reach in their consequences that forces us to abandon them. Atomic physics is a telling example: the first modern atomic model was that of the solar system. Bohr’s atom was a horse with stripes. But when numerous paradoxes arose, it quickly turned into something entirely new, a quantum system. Understanding this “new” is not easy and takes effort. This is why even the present - mostly simple and non-technical - text, would seem difficult at times.
The truth is that nobody knows for sure. Recently, MIT Technology Review published a significant article about our lack of understanding of why LLMs work so well: https://www.technologyreview.com/2024/03/04/1089403/large-language- models-amazing-but-nobody-knows-why/
In short, this is the main reason why brains are not computers. They are powerful pattern-learning & recognition machines. They don’t compute anything, they don’t need to.
i.e. not the exact measurements of the object, but its shape is what matters. Patterns include sets of similar chains of events that can be radically different in their details. For example, we all have a psychological pattern of responding to certain events that can include things as different as fear of flying and aggressive positioning against unfamiliar people. These behaviors can be part of the same pattern, but you cannot put them into a single measurement system.
There is an interesting point worth exploring about how we use AI to predict many things, including behavior. Space is limited here, but the point is that it’s a mistake. Patterns and probabilities are different animals. We can discuss the probability of a particular pattern occurring, but that is not what AI works with. AI recognizes patterns in a huge data set to respond to a real-world event, be it a prompt in ChatGPT or a dog crossing the street in front of a Tesla. It does not in any way predict what the dog will do or if a dog will suddenly appear! This is one of the most dangerous misconceptions about AI, that it can help predict anything. We can build predictive models based on AI output data in simulated situations, but this is not “using AI to predict output”. This case is more like using AI as a sort of “reality simulator” to output a series of responses to the same general prompt, to build a series of different instances of a particular pattern; we can then look at all this output and build probabilistic models, but when we do that, AI is not involved at all! Also, when hearing about “an AI model able to predict cancer based on your diet”, the word “predict” is a misnomer. What the model does is to see how well one fits in its different found patterns, some of them including cancer as a parameter.
The ridiculous idea of finding an “algorithm” to win the lottery is based mostly on the idea that probabilities work in individual cases.
To keep on with the driving analogy, it is enough to encounter a couple of times the pattern describing a driver not giving way when coming in from a secondary road. The adrenaline of avoiding an accident makes this pattern significant, even if we rarely encounter it. The “weight” of the visual pattern of a vehicle not slowing down before a crossroad stays with us and induces a pattern of heightened awareness and deceleration in us. You hit the brake without any thinking. Statistics and probabilities are mostly irrelevant.
This is a classical example in machine learning and neural networks. A really simple neural network can be train to the point to recognise by itself that a photo of Robert Plant in the 70s is that of a man; no easy task!
In fact, GPT means “Generative Pre-trained Transformer”.
In technical terms, word embedding algorithms themselves do not directly measure distances between words. Instead, they learn to map words to continuous vector representations in such a way that semantically similar words are closer together in the embedding space. In terms of general understanding, the best analogy to this is “distance”.
The Project Gutenberg eBook of Collected Papers on Analytical Psychology, by C. G. Jung. Available from: https://www.gutenberg.org/files/48225/48225-h/48225-h.htm#Footnote_125_125
Nelson DL, McEvoy CL, Schreiber TA. The University of South Florida free association, rhyme, and word fragment norms. Behavior Research Methods, Instruments, & Computers. 2004 Aug;36(3):402–7.
In an article published in 1914 in The American Journal of Psychology (Kohs, 1914), Samuel C. Kohs observes the following:
‘The process of association is, from the synthetic point of view, the keystone of our mental life. It would be folly to maintain at this date, with Hobbes, Hume, Bain and the rest, that the phenomenon of association is the all of consciousness. We must admit, however, that it is one of the basic factors making for normal mental activity. Perception, thought, action cease when the association process is interfered with. The laws of memory, of habit, of thought, are but a restatement of the laws of association.’
This is not to imply that details are not essential, sometimes a comma entirely changes the meaning of some groups of words. However, the fundamental knowledge content is there no matter how “twisted”, primitive or “bent” the phrase is if the words are associated in a pattern corresponding to some reality experienced pattern.